
Big Data has long become a default setting for most IT projects. Whether it is an enterprise solution for tracking compactor sensors in an AEC project, or a e-commerce project aimed at customers across country — gathering, managing, and then leveraging large amounts of data is critical to any business in our day and age.
In the first aforementioned scenario, we have a massive amount of data from compactor sensors that can be used for algorithms training and AI inference deployed on the edge. Also, one partly autonomous compactor equipped with the right sensor suite could generate up to 30 TB of data daily.
As for the second case, a countrywide e-commerce solution would serve millions of customers across many channels: mobile, desktop, chatbot service, assistant integrations with Alexa and Google Assistant, and other. The solution would also need to supports delivery operations, back-end logistics, supply chain, customer support, analytics, and so on.
These and many other cases involve millions of data points that should be integrated, analyzed, processed, and used by various teams in everyday decision making and long-term planning alike.
Thus, before implementing a solution, a company needs to know which of Big Data tools and frameworks would work in their case.
In this guide, we will closely look at the tools, knowledge, and infrastructure a company needs to establish a Big Data process, to run complex enterprise systems.
From the database type to machine learning engines, join us as we explore Big Data below.
Big Data & The Need for a Distributed Database System
In the old days, companies usually started system development from a centralized monolithic architecture. The architecture worked well for a couple of years, but was not suitable for the growing number of users and high user traction.
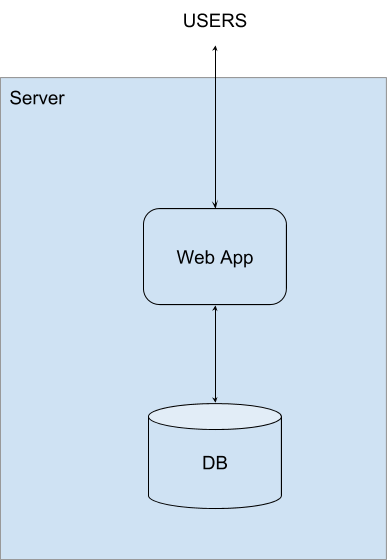
Centralized System
Then, software engineers started scaling the architecture vertically by using more powerful hardware increasing — with more RAM, better CPUs, and larger hard drives (there were no SSDs at that moment in time).
When the system got more load, the app logic and database could be split to different machines.
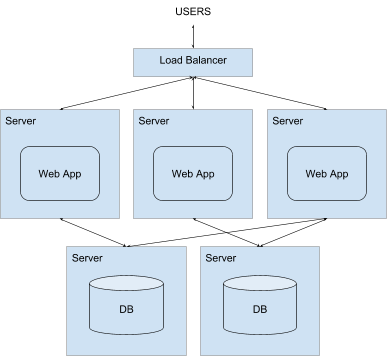
Multiple Apps and Databases
After some time, we proceeded with app logic and database replication, the process of spreading the computation to several nodes and combining it with a load balancer.
All this helped companies manage growth and serve the user. On the other hand, the process increased the cost of infrastructure support and demanded more resources from the engineering team, as they had to deal with failures of nodes, partitioning of the system, and in some cases data inconsistency that arose from misconfigurations in the database or bugs in application logic code.
At this point, software engineers faced the CAP theorem and started thinking what is more important:
a) Consistency: every read always receives the most recent write or error, but never the old data.
b) Availability: every request receives a response, but does not guarantee that it contains recent data.
c) Partition Tolerance: the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
In particular, the CAP theorem states that it is impossible for a distributed data store to simultaneously provide more than two of the above guarantees.
But usage continued to grow and companies and software engineers needed to find new ways to increase the capacity of their systems. This brings us to the realm of horizontally scalable, fault-tolerant, and highly available heterogeneous system architectures.
Horizontally Scalable Infrastructure
Distributed File System (DFS) as a main storage model
Google File System (GFS) served as a main model for the development community to build the Hadoop framework and Hadoop Distributed File System (HDFS), which could run MapReduce task. The idea is to take a lot of pieces of heterogeneous hardware, and run a distributed file system for large datasets.
As the data is distributed among a cluster’s many nodes, the computation is in the form of a MapReduce task. MapReduce and others schedulers assign workloads to the servers where the data is stored, and which data will be used as an input and output sources — to minimize the data transfer overhead. This principle is also called data locality.
Hadoop clusters are designed in a way that every node can fail and system will continue its operation without any interruptions. There are internal mechanisms in the architecture of the overall system that enable it to be fault-tolerant with fault-compensation capabilities.
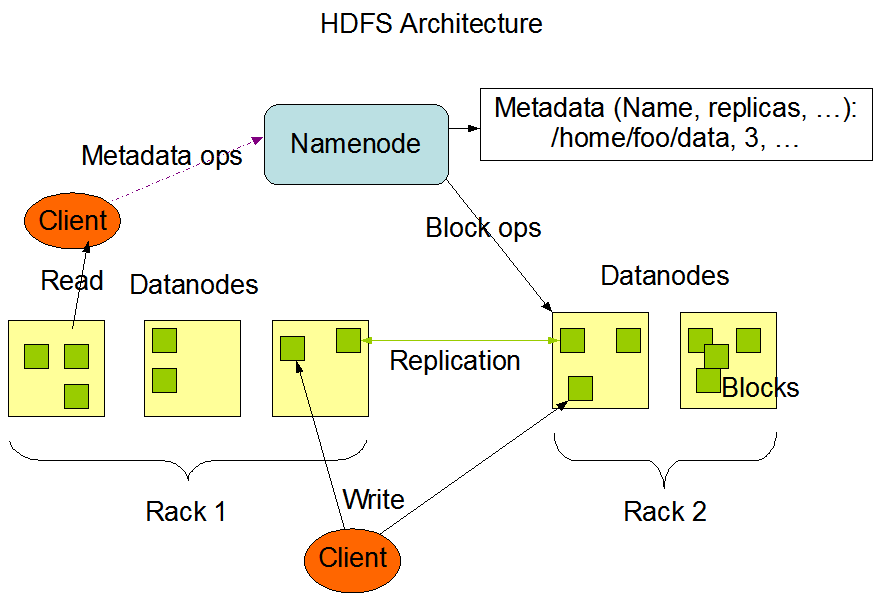
Distributed HDFS Architecture
Files stored in HDFS are divided into small blocks and redundantly distributed among multiple servers with a continuous process of balancing the number of available copies according to the configured parameters.
Here is the list of all architecture assumptions of HDFS architecture:
- Hardware failure is a norm rather than an exception
- Streaming data access
- Large data sets with a typical file as large as gigabytes and terabytes
- Simple coherency model that favors data appends and truncates but not updates and inserts.
- Moving computation is cheaper than moving data
- Portability across heterogeneous hardware and software platforms
Hadoop HDFS is written on Java and can be run on almost all major OS environments.
The number of nodes in major deployments can reach hundreds of thousands with the storage capacity in hundreds of Petabytes and more. Apple, Facebook, Uber, Netflix all are heavy users of Hadoop and HDFS.
HBase: More Than A Distributed Database Architecture
But in order to improve our apps we need more than just a distributed file system. We need to have a database with fast read and write operations (HDFS and MapReduce cannot provide fast updates because they were built on the premise of a simple coherency model).
Again, Google has built BigTable, which has a wide-column database that works on top of GFS and features consistency and fast read and write operations. So, the open-source community has built HBase — an architecture modeled after BigTable’s architecture and using the ideas behind it.
HBase a NoSQL database that works well for high throughput applications and gets all capabilities of distributed storage, including replication and fault and partition tolerance. In other words, it is a great fit for hundreds of millions (and billions) of rows.
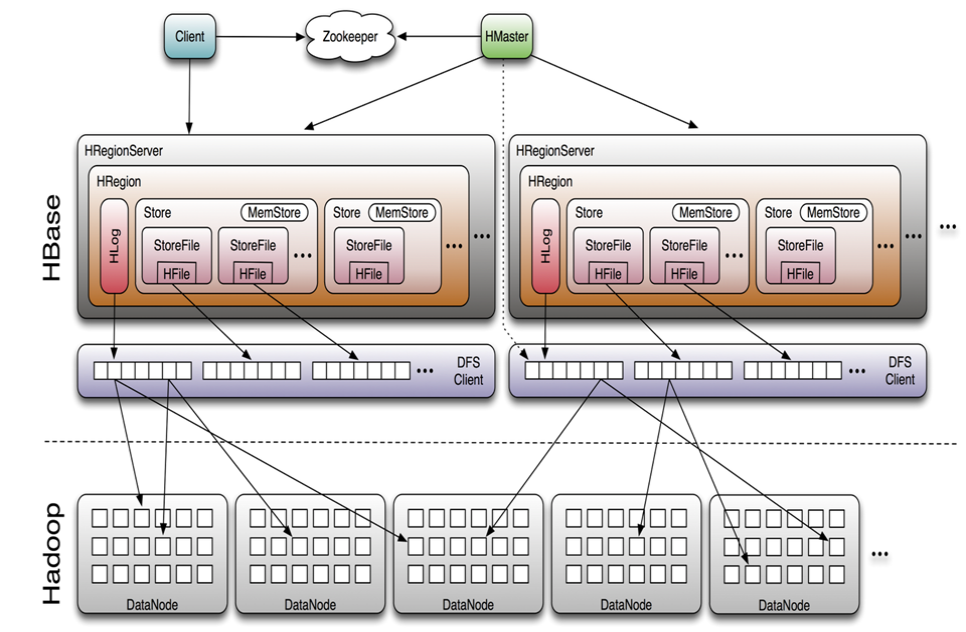
HBase Architecture on top of the Hadoop (Source)
Cassandra
There is also Cassandra, an evolution of HBase that is not dependent on HDFS and does not have a single master node. Cassandra avoids all the complexities that arise from managing the HBase master node, which makes it a more reliable distributed database architecture.
Cassandra is also better in writes than HBase. More so, it better suits the always-on apps that need higher availability. Remember the CAP theorem and trade-off between consistency and availability?
Machine Learning Engines & Tools for Big Data Analytics
Hive
Hive is one of the most popular Big Data tools to process the data stored in HDFS, providing reading, writing, and managing capabilities for stored data. Other important features of Hive are providing the structure on top of stored data and using SQL as the query language.
Hive’s main use cases involve data summarization and exploration, which can be turned into actionable insights. The specialized SQL syntax is called HiveQL, and it is easy to learn for one who is familiar with the standard SQL and the notion of key-value nature of the data, rather than standard relational RDBMS. However, for highly concurrent BI workloads, it is better to use Apache Impala, which can work on top of Hive metadata but with more capabilities.
Spark
The best Big Data tools also include Spark. Spark is a fast in-memory data processing engine with an extensive development API that allows data workers to efficiently execute streaming, machine learning, and SQL workloads with fast iterative access to stored data sets.
Spark can be run in different job management environments, like Hadoop YARN or Mesos. It is also available in a Stand Alone mode, where it uses built-in job management and scheduling utilities.
YARN
YARN is a resource manager introduced in MRV2, which supports many apps besides Hadoop framework, like Kafka, ElasticSearch, and other custom applications.
Spark MLlib
Spark MLlib is a machine learning library that provides scalable and easy-to-use tools:
- Common learning algorithms — classification, regression, clustering, and filtering
- Feature extraction pipelines, transformation, dimensionality reduction
- Persistence for algorithms pipelines & linear algebra and statistics utilities
KNIME Analytics Platform
KNIME is helpful for visualization of data pipelines and ETL processing via modular components. With minimal programming and configuration, KNIME can connect to JDBC sources and combine it in one common pipelines.
Presto SQL
Interactive features of distributed data processing can be achieved with Presto SQL query engine that can easily run analytics queries against gigabytes and petabytes of data. The tool was developed at Facebook, where it was used on a 300 PB data warehouse with 1000 employees working in a tool daily and executing 30000 queries that in total scan up to one PB each daily. This puts Presto high up in the list of solid tools for Big Data processing.
Big Data Tools for Streams & Messages
Another modality of data processing is handling data as streams of messages. This typically involves operations connected to data from sensors, ads analytics, customer actions, and high volumes of data from sensors like cameras of LiDARs from autonomous systems.
Kafka
Kafka is currently the leading distributed streaming platform for building real-time data pipelines and streaming apps.
The use cases include:
- Messaging: traditional message broker pattern of data processing
- Website Activity Tracking: real-time publish-subscribe feeds in domains of page views, searches, and other user interactions.
- Metrics: operational monitoring data processing.
- Log Aggregation: collecting physical log files and store them for further processing.
- Stream Processing: multi-stage data processing pipelines.
- Event Sourcing: support of apps built with stored event sequences that can be replayed and applied again for deriving a consistent system state.
- Commit Log: the type of data stored in distributed system that ensures the re-syncing mechanism.
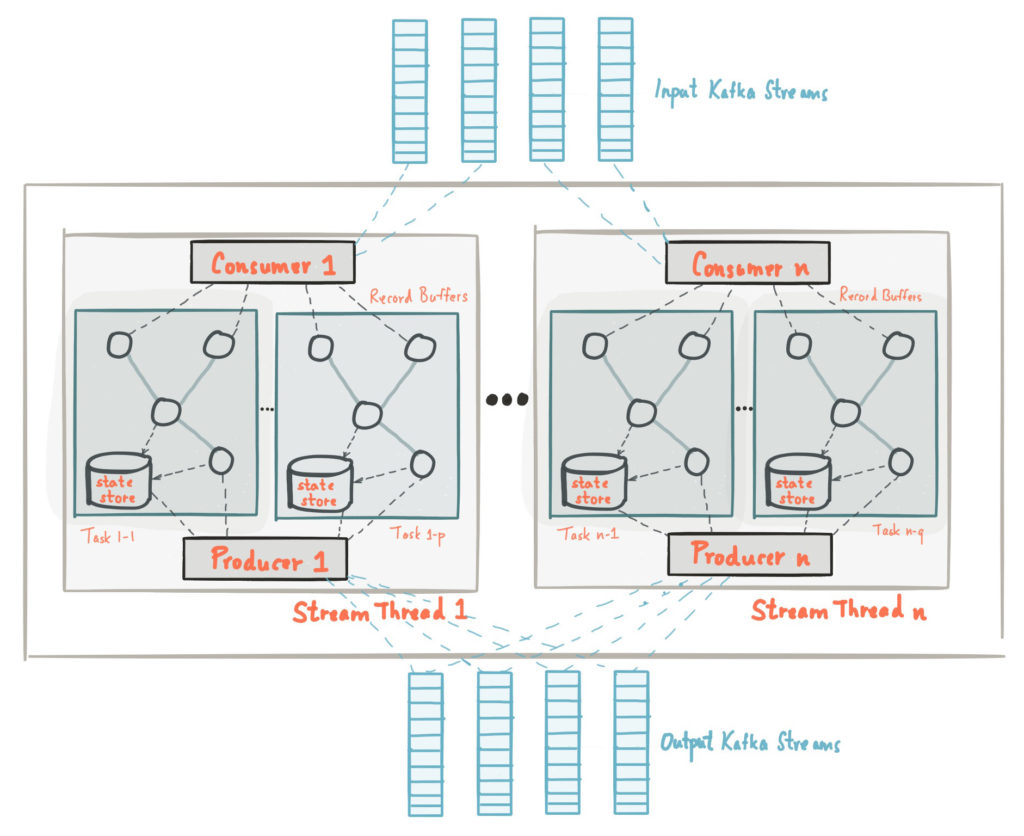
Kafka Streams Architecture (Source)
Apache Storm
Apache Storm is a distributed stream processor that further processes the messages coming from Kafka topics. It is common to call Storm a “Hadoop for real-time data.” This distributed database technology is scalable, fault-tolerant, and analytic.
Apache NiFi
For intuitive web-based interface that supports scalable directed graphs of data routing, transformation, and system mediation logic, one can use Apache NiFi. It is also simpler to get quick results from NiFi than from Apache Storm.
NiFi Web Interface
Conclusion
The modern big data technologies and tools are mature means for enterprise Big Data efforts, allowing to process up to hundreds of petabytes of data. Still, their efficiency relies on the system architecture that would use them, whether it is an ETL workload, stream processing, or analytical dashboards for decision-making. Thus, enterprises should to explore the existing open-source solutions first and avoid building their own systems from ground up at any cost — unless it is absolutely necessary.
If you need help in choosing the right tools and establishing a Big Data process, get in touch with our experts for a consultation.


